Der optimale Relaunch-Stage: Robots.txt, Login, Noindex oder was?
Ein Staging Server ist bei einem Relaunch-Projekt unerlässlich, damit man vor dem Go-Live der neuen Website alles prüfen kann. Doch was ist dabei genau zu beachten, damit der Stage z. B. nicht von Google indexiert wird?
Wer seine Website erneuern möchte, wird hierzu in der Regel einen Staging Server („Stage“) erstellen (lassen). So kann man auf die Website zugreifen und ihr beim Entstehen zusehen. Fehler werden ausgebessert, Inhalte werden hinzugefügt – solange, bis die Freigabe und damit der Go-Live erfolgen. In der Regel ist der Stage über eine eigene URL, häufig auch auf eigenem Server, abrufbar. Es bieten sich Subdomains wie neu.unternehmen.de oder kunde.agentur.de an.
Ein Stage ist aber vor allem wichtig, damit alle SEO-Anforderungen an die neue Website geprüft werden können, bevor diese live geht – und bevor eventuelle Fehler Schaden anrichten.
Alles prüfen!
Dabei ist wichtig, dass auf dem Stage alles so ist, wie es später auch auf der realen Website sein wird. Also:
- Die robots.txt sollte die Anweisung zur Steuerung des Crawlers enthalten.
- Das Robots-Meta-Tag sollte korrekt befüllt sein, um z. B. bestimmte Seiten von der Indexierung auszuschließen.
- Für alle geänderten URLs sollte es 301-Umleitungen geben.
- Die Canonical Tags sollten korrekt vorhanden sein (und natürlich noch auf den Stage selbst zeigen).
- Bei internationalen Websites sollten die hreflang-Tags vorhanden sein.
- Markup (schema.org …) sollte in den Seiten implementiert sein.
- Die XML- und falls sinnvoll News-Sitemaps sollten für den Stage verfügbar sein.
- …
Wenn also auf dem Stage alles implementiert ist, können die einzelnen Aspekte noch vor dem Go-Live optimal geprüft werden, z. B. mit den folgenden Tools:
- Google Search Console (vor allem die Funktion „Abruf wie durch Google“, um das korrekte Rendering einer Seite zu überprüfen)
- Screaming Frog SEO Spider (Crawling der gesamten Website, um Probleme zu finden, z. B. leere Seitentitel, irrelevante URL-Parameter …)
- Google Test-Tool für strukturierte Daten (Überprüfung des Markup)
- Tools zum Testen der hreflang-Tags (hreflang.ninja, hreflang.org …)
Überprüfung der Weiterleitungen
Vor allem das Austesten der URL-Weiterleitungen ist extrem wichtig, da sonst beim Go-Live massive Traffic- und Ranking-Einbußen drohen. Auf dem Stage sollten deshalb alle URL-Weiterleitungen existieren, die dann auch beim Go-Live wichtig sind. (Mehr dazu übrigens im nächsten suchradar.)
Zum Testen der Weiterleitungen bieten sich Tools wie httpstatus.io an, mit denen man max. 100 URLs gleichzeitig überprüfen kann. Größere Mengen können z. B. mit dem Screaming Frog SEO Spider überprüft werden.
Doch was genau muss eigentlich geprüft werden? Ein Beispiel:
Die alte Seite http://www.website.de/alt/ soll nach dem Go-Live unter der URL http://www.website.de/neu/ erreichbar sein. Dann muss es eine 301-Weiterleitung geben, die /alt/ auf /neu/ umleitet. Wenn man nun einen Stage wie stage.website.de hat, würde man die URL http://stage.website.de/alt/ überprüfen, die korrekterweise auf http://stage.website.de/neu/ weiterleiten müsste.
Es muss natürlich nicht nur geprüft werden, ob es sich tatsächlich um eine 301-Weiterleitung handelt, sondern auch, ob auf eine möglichst passende neue Seite weitergeleitet wird. Die Umleitung aller alten URLs auf die neue Startseite wäre eine extrem schlechte Lösung.
Fünf Methoden, eine Website zu sperren
Ein Stage ist also sehr wichtig, um die Eigenschaften einer Website vor dem Go-Live prüfen zu können. Dabei muss aber natürlich beachtet werden, dass typischerweise der Stage nicht von Google indexiert werden sollte, damit Nutzer die oft unfertigen Seiten nicht in Suchergebnissen anklicken. Der Stage muss also in jedem Fall für Suchmaschinen, oft auch für fremde Nutzer, komplett gesperrt werden.
Grundsätzlich gibt es für das Sperren einer Website fünf unterschiedliche Methoden:
1. robots.txt
Über die Datei robots.txt kann man festlegen, dass Suchmaschinen-Crawler bestimmte Seiten einer Website nicht herunterladen („crawlen“) dürfen. Mit den folgenden zwei Anweisungen kann man dort alle Seiten fürs Crawling sperren:
User-Agent: *
Disallow: /
Diese Methode ist sicherlich die einfachste, weil nur zwei Zeilen in eine Textdatei geschrieben werden müssen. Leider verhindert die robots.txt zwar das Crawling, nicht aber unbedingt die Indexierung. Der Googlebot kann die entsprechenden Seiten nicht herunterladen und verfügt damit über keine Informationen. In solchen Fällen legt Google aber manchmal auch Leereinträge im Index an. Dann ist der Stage theoretisch im Index vertreten – wenn es auch sehr unwahrscheinlich ist, dass jemand auf einen solchen Eintrag klickt.
Und: Typischerweise erhält die spätere Website auch eine robots.txt-Datei, um bestimmte irrelevante Seiten für Suchmaschinen zu sperren. Wenn man über die beiden genannten Zeilen auf dem Stage alles sperrt, kann man vor dem Go-Live der Website nicht prüfen, ob die robots.txt auch vollkommen korrekt ist. Über Umwege kann man das natürlich trotzdem erreichen: Mit dem Screaming Frog SEO Spider kann man z. B. ab Version 7 eine eigene robots.txt hinterlegen und die Korrektheit der Datei damit trotzdem überprüfen. Ein bisschen umständlich ist dieser Weg aber schon.
2. Robots-Meta-Tag „noindex“
Das Robots-Meta-Tag „noindex“ sorgt dafür, dass eine bestimmte Seite zwar von Google heruntergeladen, aber nicht in den Index befördert wird. Diese Seiten sind also unauffindbar.
Alternativ zum Robots-Meta-Tag gibt es auch die Möglichkeit, dieselben Informationen über den HTTP-Header zu kommunizieren (siehe https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag?hl=de). In manchen Fällen ist diese Alternative leichter zu implementieren. Man sollte aber darauf achten, dass man nicht beide Möglichkeiten miteinander kombiniert, also unterschiedliche Anweisungen im Meta-Tag und im HTTP-Header platziert, weil dies dazu führen kann, dass ein an nur einer Stelle platziertes „noindex“ ignoriert wird.
Analog zur robots.txt gilt übrigens auch hier: Wenn alle Seiten ein „noindex“-Tag haben, kann man die Robots-Meta-Tags der späteren Website nicht mehr vor dem Go-Live überprüfen.
3. HTTP-Login
Ein HTTP-Login (formal richtig: Basic HTTP Authentication) ist wohl die sicherste und oft einfachste Methode, eine Website komplett für fremde Nutzer und für Suchmaschinen-Crawler zu sperren. Da der Googlebot den dazugehörigen Login nicht kennt und auch bei Kenntnis nicht eingeben würde, hat Google so überhaupt keinen Zugriff auf die jeweiligen Seiten.
Einen Login kann man z. B. über die .htaccess-Datei generieren, indem man eine separate Datei für den Login generiert und dann Codes wie den folgenden in der .htaccess-Datei platziert:
AuthType Basic
AuthName “Stage für meine Website”
AuthUserFile .htpasswd
Require valid-user
Nachteilig kann ein HTTP-Login dann sein, wenn man viele unterschiedliche Tools nutzen möchte, um den Stage bzw. einzelne Seiten zu prüfen. Denn leider unterstützen nicht alle Tools die Eingabe der Login-Daten. Je nach Tool hat man vielleicht auch etwas Angst, Benutzer und Passwort preiszugeben.
4. Formular-Login
Eine andere Variante wird von manchen Content-Management- oder Shop-Systemen angeboten, bei denen man einen Login innerhalb einer Website eingeben muss (Beispiel siehe Abbildung 1). Ein Formular-Login ist grundsätzlich die schlechteste Wahl, weil nur ganz wenige Tools sie unterstützen (siehe Tabelle 1).
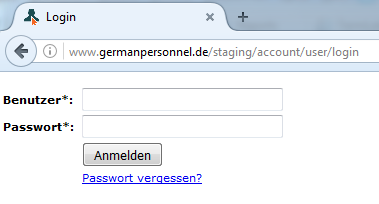
Abbildung 1: Ein Formular zum Login – für SEO-Relaunche die schlechteste Lösung, weil nur wenige Tools das Formular überwinden können.
5. IP-Sperre
Eine IP-Sperre wird in der Regel so aufgebaut, dass ein Stage nur von bestimmten IP-Adressen aus aufgerufen werden kann. In der Regel wird man dort dann die IP-Adressen des eigenen Unternehmens sowie beteiligter Agenturen freischalten. Möglich wird das z. B. über Anweisungen in der .htaccess-Datei. Wer z. B. erreichen möchte, dass die Website nur für die IP-Adresse 6.7.8.9 erreichbar ist, könnte den folgenden Code verwenden:
Order deny,allow
Deny from all
Allow from 6.7.8.9
Satisfy any
Mit einer IP-Sperre schließt man aber auch erstmal sämtliche Tools aus. Sicherlich kann man die IP-Adressen oder -Blöcke freischalten – aber dafür muss man diese auch erst einmal kennen. Gerade Google hat für seine unterschiedlichen Tools auch unterschiedliche Adressen. Wer also mit einer Vielzahl an Tools auf eine auf IP-Basis gesperrte Website zugreifen möchte, hat in der Regel sehr viel Arbeit vor sich.
Im Vergleich
Tabelle 1 vergleicht die fünf vorgestellten Methoden, um eine Website für Suchmaschinen und/oder Nutzer zu sperren. Welche Methode man wählt, hängt natürlich zunächst einmal von den Möglichkeiten der Website ab – und danach von den Tools, die man verwenden möchte.
Wer möchte, dass eine Website auf gar keinen Fall für fremde Nutzer zugänglich und abrufbar ist, muss sich dabei für einen Login (bevorzugt: HTTP-Login) oder sogar die IP-Sperre entscheiden. Wenn es ausreicht, dass eine Website nicht in den Suchergebnissen erscheint, ist die Nutzung von „noindex“ sicherlich die allerbeste Wahl.
| Welche Methode kommt zum Einsatz? | |||||
| Welches Tool wird benutzt? | robots.txt | Robots-Meta-Tag “noindex” | HTTP-Login | Formular-Login | IP-Sperre |
| Google Search Console (vor allem „Abruf wie durch Google“) | – | ja | – | – | (ja) (IP des Google-Crawlers muss freigeschaltet werden) |
| Screaming Frog SEO Spider | ja (Option „Ignore robots.txt“ muss gesetzt werden) |
ja (Option „Respect noindex“ muss ausgeschaltet werden) |
ja (Option „Request Authentication“ muss gesetzt werden) |
ja (ab Version 7 möglich: „Authentication > Forms Based“) |
(ja) (IP des Rechners muss freigeschaltet werden) |
| Google Test-Tool für strukturierte Daten | ja | ja | – | – | (ja) (IP des Google-Crawlers muss freigeschaltet werden) |
| httpstatus.io | ja | ja | ja | – | (ja) (IP des Dienstes muss freigeschaltet werden) |
| Tools zum Testen der hreflang-Tags (vor allem: hreflang.ninja, hreflang.org …) | ja | ja | – | – | (ja) (IP des Dienstes muss freigeschaltet werden) |
Tabelle 1: Welches Tool kann mit welchen Sperrmethoden arbeiten?
Fazit
Welche der fünf Lösungen zum Einsatz kommt, hängt immer vom Einzelfall ab. Unternehmen sollten aber vorher darüber nachdenken, um dann in der hektischen Phase kurz vor dem Go-Live nicht überraschend festzustellen, dass es nicht möglich ist, ein bestimmtes Tool zu nutzen oder eine bestimmte Eigenschaft zu überprüfen. In vielen Fällen bietet sich einfach die „noindex“-Lösung an – alternativ auch der HTTP-Login, um nicht nur Suchmaschinen, sondern auch fremde Nutzer konsequent auszusperren.
Übrigens: Dieser Artikel stammt aus der Ausgabe 64 unseres Magazins suchradar. Falls Sie die Ausgabe noch nicht kennen, können Sie diese und alle früheren Ausgaben im suchradar-Archiv kostenlos herunterladen.

Markus Hövener
Markus Hövener ist Gründer und SEO Advocate der auf SEO und SEA spezialisierten Online-Marketing-Agentur Bloofusion. Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Buchautor, Podcaster und Autor vieler Artikel und Studien rund um SEO.
Markus hat vier Kinder, spielt in seiner Freizeit gerne Klavier (vor allem Jazz) und genießt das Leben.
Neueste Artikel von Markus Hövener (alle ansehen)
- SEO-Trainee-Programme: Ganz einfach SEOs ausbilden? [Search Camp 316] - 16. April 2024
- SEO-Monatsrückblick März 2024: Google Updates, Search Console + mehr [Search Camp 315] - 2. April 2024
- Recap zur SMX München: Die wichtigsten Take-Aways [Search Camp 314] - 19. März 2024
- Sichtbarkeit und/oder Traffic gehen nach unten: Woran kann’s liegen? [Search Camp 313] - 12. März 2024
- Wie wichtig ist es, allen SEO-News zu folgen? [Search Camp 312] - 5. März 2024
