SEO für Einsteiger – Teil 1: Die Funktionsweise von Suchmaschinen
Um zu verstehen, wie man eine Website für Suchmaschinen optimieren kann, lohnt es sich zunächst, mehr über Suchmaschinen zu erfahren. Im ersten Teil der SEO-Einsteigerserie möchte ich deshalb näher auf die Funktionsweise von Google & Co. eingehen. Letzten Endes dreht sich alles um die drei Begriffe Crawling, Indexing und Serving, mit denen ich mich im Rahmen der unten stehenden Fragen auseinandersetzten möchte.
Crawling
1. Was geschieht vor einer Suchanfrage?
Indexing
2. Was geschieht mit den Daten, die beim Crawl gesammelt werden?
3. Kann man steuern, was die Bots crawlen dürfen und was im Index landet?
4. Wie entscheiden Suchmaschinen, welche Informationen für den Nutzer relevant sind?
Serving
5. Was geschieht nun bei einer Suchanfrage?
6. Kann man das angezeigte Ergebnis einer Suchmaschine optimieren?
8. Was ist ein Featured Snippet?
9. Welche Arten von Informationen werden bei einer Suchanfrage angezeigt?

Indexing
1. Was geschieht vor einer Suchanfrage?
Lange bevor dem Nutzer ein Suchergebnis ausgespielt wird, beginnt das Crawling durch einen Webcrawler. Ein Webcrawler ist nichts anderes als ein Computerprogramm, das Webseiten durchsucht und diese analysiert. Solche Programme sind z. B. der Googlebot oder der Bingbot.
Die Bots starten ihren Crawl mit wenigen bekannten Seiten und folgen dann Links, die sie auf den Webseiten entdecken. Das sind sowohl interne Links auf der jeweiligen Seite, als auch Links zu externen Websites. So finden die Crawler immer neues Futter und immer mehr Webseiten werden durchsucht. Neben den Links sammelt der Crawler alles, was er finden kann: HTML-Code, Bilder, URLs, Sitemaps und PDF-Dateien.
Die Arbeit wird jedoch nicht von einem Bot alleine verrichtet. Es gibt Bots für bestimmte Medien (Bilder, Videos und News), unterschiedliche Devices (Desktop-Computer und Smartphone) sowie Ads.
Crawling
2. Was geschieht mit den Daten, die beim Crawl gesammelt werden?
Die Ergebnisse des Crawls fließen in eine Datenbank, den Index. Welche Daten tatsächlich im Index landen, können Seitenbetreiber über die Google Search Console ermitteln. Der Index ist nichts anderes als ein großes Verzeichnis, vergleichbar mit dem eines riesigen Lexikons, aller gecrawlten Seiten.
Beim diesem Vorgang, dem Indexing, werden im Cache die Seiten mit den wichtigen Seitenelementen (Titel, Meta Description, HTML-Gerüst und Texten) gespeichert. Hinzu kommen weitere Informationen. Im Fall von Google ist das zum Beispiel der PageRank, ein Algorithmus, der die Verlinkungsstruktur einer Website bewertet und von Larry Page und Sergei Brin geschaffen wurde.
3. Kann man steuern, was die Bots crawlen dürfen und was im Index landet?
Die Bots lassen sich über die robots.txt, einem Dokument, welches unter www.meinehomepage.de/robots.txt zu finden ist, steuern. Einzelne Seiten oder Verzeichnisse können damit vom Crawl ausgeschlossen werden. Außerdem lassen sich bestimmte Arten von Bots ausschließen. Das verhindert jedoch nicht ein Auftauchen der Seite in den Suchergebnissen.
Um die Indexierung komplett zu verhindern kann das Robots-Meta-Tag „noindex“ verwendet werden. Damit Bots dies erkennen können, muss die Seite gecrawlt werden. Es ergibt also keinen Sinn, Seiten zeitgleich per robots.txt und dem Robots-Meta-Tag zu sperren.
Wer sich näher mit dem Thema beschäftigen möchte, findet in unserem Beitrag „Wie man Crawling und Indexierung steuern kann“ weitere Informationen.
4. Wie entscheiden Suchmaschinen, welche Informationen für den Nutzer relevant sind?
Suchmaschinen möchten ihren Nutzern die relevantesten und qualitativ besten Informationen anbieten. Welche Informationen für den Nutzer relevant sind, ermitteln Suchmaschinen nach unterschiedlichen Kriterien. So ermittelt Google beispielsweise anhand von Fragen, wie z. B. „Wie häufig erscheinen Keywords?“ oder „Wie hoch ist die Qualität der Website?“, einen Overall Score für die Seite. Je nach ermittelter Relevanz und Art der Suchanfrage legen die Algorithmen der Suchmaschinen fest, in welcher Reihenfolge die Ergebnisse ausgegeben werden.
In den Google-Algorithmus fließen 200 Qualitätskriterien ein, nach denen die Seiten bewertet werden. Über die genaue Bewertung einzelner Kriterien gewähren Suchmaschinenbetreiber jedoch keine genauen Einblicke, um Manipulationen zu vermeiden. Des Weiteren können die Google Entwickler – spätestens seit der Nutzung von RankBrain – selbst nicht mehr nachvollziehen, was der Algorithmus als Ranking-Faktor mit einbezieht, weil RankBrain mit künstlicher Intelligenz arbeitet und selbstlernend ist.
Serving
5. Was geschieht nun bei einer Suchanfrage?
Wird nun eine Suchanfrage über eine Suchmaschine abgeschickt, durchsuchen Algorithmen den Index nach den geforderten Informationen. Grundsätzlich ist zu beachten, dass bei einer Suchanfrage nicht das Web durchsucht wird, sondern der Webindex der jeweiligen Suchmaschine.
Die Ergebnisse werden uns beim Serving in einer Trefferliste, der sogenannten SERP (Search Engine Result Page), serviert. Jedes Suchergebnis wird in Form eines Snippets ausgegeben.
6. Kann man das angezeigte Ergebnis einer Suchmaschine optimieren?
Das Snippet setzt sich aus dem Titel-Tag, der URL und der Meta Description zusammen. Für eine saubere Darstellung empfiehlt es sich daher, einen prägnanten Seitentitel (Titel-Tag) und eine nutzerorientierte Meta Description zu vergeben. Wichtige Informationen sollten in Beschreibungstexten ganz vorne erscheinen, um auch auf mobilen Endgeräten, bei denen der Beschreibungstext gekürzt wird, eine nutzerorientierte Darstellung zu haben. Außerdem sollten Seitentitel und Meta Description immer unique sein, damit Suchmaschinen diese thematisch zuordnen können. Je nach Suchanfrage weichen Suchmaschinen teilweise von diesen Informationen ab und bauen sich ihr eigenes Snippet zusammen. Es gibt also, abhängig von der Suchanfrage, keine Garantie, dass die hinterlegten Informationen auch ausgegeben werden. In den meisten Content Management Systemen lassen sich diese Inhalte leicht über die Seiteninformationen pflegen.
7. Was ist ein Sitelink?
Stellt Google fest, dass ein Suchergebnis besondere Relevanz für den Nutzer hat, wird dies durch die Anzeige eines Sitelinks belohnt. Für den Nutzer erleichtert das die Navigation, denn er kann nun die passende Unterseite direkt ansteuern. Das ist zum Beispiel häufig der Fall, wenn nach Markennamen gesucht wird.
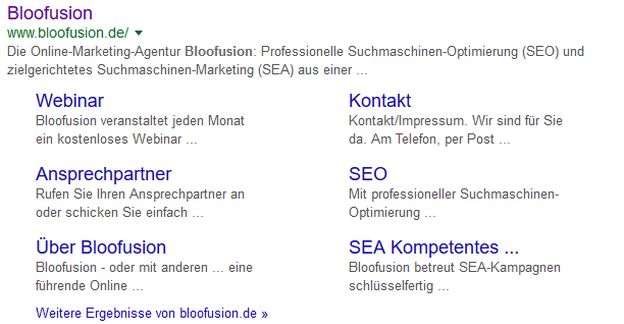
Sitelinks von Bloofusion
8. Was ist ein Featured Snippet?
Ein Featured Snippet wird quasi auf Position 0 der ersten SERP ausgegeben und erscheint somit vor den übrigen Ergebnissen. Dahinter steckt die Idee, dass der Suchende eine Antwort auf eine Frage möglichst schnell findet. Somit können entsprechende Antworten der ersten SERP, also der Top 10 Suchergebnisse, auf die oberste Position rutschen und fallen dem User direkt ins Auge.
Ausführliche Informationen zu Featured Snippets finden Sie im Blog Beitrag von meinem Kollegen Maximilian Geisler: „Featured Snippets mit einer cleveren Antwort an die Spitze der Suchergebnisse “.
9. Welche Arten von Informationen werden bei einer Suchanfrage angezeigt?
Suchanfragen lassen sich in drei Arten gliedern: transactional, navigational und informational. Entsprechend der Art spielt die Suchmaschine dann relevante Ergebnisse aus:
- Transactional impliziert immer eine Handlungsabsicht mit einem kommerziellen Hintergrund, wie z. B. „Sportschuh kaufen“.
- Navigational ist eine Anfrage nach einer bestimmten Website, wie z. B. „YouTube“.
- Informational sind Anfragen, bei denen der Nutzer auf der Suche nach einer konkreten Information oder Lösung ist, wie z. B. „Kaffee kochen“ oder „Blumen gießen“.
10. Fazit
Die Optimierung von Seiten für die Suchmaschine ist komplex. Versteht man jedoch die Funktionsweise von Suchmaschinen, werden schnell viele Potenziale deutlich, die sich aus Optimierungsmaßnahmen ergeben können. Viele Dinge, wie z. B. die Darstellung der Suchergebnisse lassen sich, je nach Anzahl der Seiten, leicht konfigurieren und bringen User schneller dazu, auf das Snippet zu klicken. Das sorgt für mehr Traffic und steigert die Chance auf eine mögliche Conversion.
Es zeigt sich außerdem, wie wichtig es ist, aus der Sicht des Nutzers einer Suchmaschine zu denken und im Hinterkopf zu behalten, was bekommt der Nutzer von meinen Informationen auf der Website bereits in der Suchmaschine angezeigt. Daran schließt sich die folgende Frage an: Was könnte den Nutzer animieren, auf genau mein Suchergebnis zu klicken?
In diesem Sinne, viel Spaß beim Optimieren!
Alle Artikel aus der Serie SEO für Einsteiger
Teil 1: Die Funktionsweise von Suchmaschinen
Teil 2: Wie baue ich meinen ersten Link auf?
Teil 3: Keywords, Keywords, Keywords
Teil 4: Wo fange ich eigentlich mit SEO an?
Teil 5: Tipps für die Homepage
Teil 6: Strukturierte Daten, Markups & co.

Andreas Engelhardt
Andreas Engelhardt ist Head of Digital Analytics + CRO bei der Online-Marketing-Agentur Bloofusion.
Dort berät er Kunden bei der Webanalyse und der Optimierung ihrer Seiten für mehr Sales und Leads. Zudem bloggt er regelmäßig im Bloofusion Blog.
Andreas Engelhardt ist unter anderem in den folgenden sozialen Netzwerken zu finden:
Neueste Artikel von Andreas Engelhardt (alle ansehen)
- Google Consent Mode Version 2 – Alles, was du wissen musst - 1. März 2024
- Recap „Conversion Day 2023“ - 20. September 2023
- [GA4] Der richtige Umgang mit Bot-Traffic - 6. September 2023
- Optimiere deine Datenanalyse: Verknüpfe Google Analytics 4 mit BigQuery - 17. Mai 2023
- GA4: ja, nein oder vielleicht? - 27. April 2023

Juli 26th, 2017 at 22:52
Besten Dank für den Artikel zum Thema SEO bzw. der Suchmaschinenoptimierung. Habe deinen Artikel erst mal einer bekannten Fotografien weitergeben, da der Artikel wirklich sehr einfach und gut verständlich geschrieben ist.
Gruß aus Bremen