SEO + HTTP-Header: Was musst du wissen?
Das HTTP-Protokoll versteckt sich in der Regel gut vor uns. Der Browser macht das schon für uns. Und doch kann es ab und zu sinnvoll sein, mal einen Blick in die Kommunikation zwischen Web-Server und Browser/Bot zu werfen. Denn SEO-relevante Informationen können sich in diesem „unsichtbaren“ Teil durchaus befinden.
Was ist ein HTTP-Header?
Wenn von einem Web-Server über HTTP eine Seite oder eine Ressource (Bild, Font …) angefragt wird, schickt der Browser (oder auch ein Bot) eine Anfrage hin. Für diese Anfrage wird ein Request geschickt, der in einer festgelegten Notation beschreibt, was genau man eigentlich möchte. In diesem Request können aber auch noch andere Informationen mitgeschickt werden, z. B. Cookies.
Der Server schickt dann die gewünschte Information – stellt dem aber einen Response Header voran, der genauere Angaben zu den Daten enthält (z. B. Dateigröße, Content-Type und vieles mehr).
Ein Beispiel
Wenn man von der Website www.abc.de die Seite /grundlagen abrufen möchte, könnte man über HTTP den folgenden Header verschicken:
GET /grundlagen HTTP/1.1
Host: www.abc.de
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0
Accept: text/html
Der Server könnte dann wie folgt antworten:
HTTP/1.1 200 OK
Content-Length: 123456
Content-Type: text/html;charset=UTF-8
Mit anderen Worten: Die Seite /grundlagen ist verfügbar (Code 200), hat den Typ „text/html“ und ist insgesamt 123456 Bytes groß.
Von dieser Kommunikation zwischen Server und Client bekommt man bei der Nutzung eines Web-Browsers nichts mit. Ähnlich wie bei anderen Protokollen wie IMAP oder FTP unterhalten sich hier eben Maschinen – eine Kommunikation, die für den menschlichen Nutzer ohnehin keinen relevanten Mehrwert hätte.
Warum sind HTTP-Header für SEO wichtig?
Wie man bei dem fiktiven Beispiel oben sehen kann, werden über den HTTP-Header vor allem zwei Informationen geliefert: der Response Code und der Content Type. Damit eine HTML-Seite korrekt indexiert werden kann, sollte hier ein gültiger HTTP-Code (also in der Regel 200) geliefert werden. Außerdem sollte der Typ „text/html“ gesetzt sein, damit der Inhalt korrekt als HTML-Seite erkannt werden kann.
Beim Content Type kommt es eigentlich nie zu Problemen, aber Response Codes können schon für Probleme sorgen. So gibt es durchaus einige Setups, bei denen eine nicht mehr existente Seite, die eigentlich einen HTTP-Code 404 (nicht mehr existent) liefern sollte, einen Code 200 generiert – ein sogenannter „Soft 404“.
Außerdem können über die HTTP-Header noch einige weitere Informationen geliefert werden, die SEO-relevant sind:
- Canonical (siehe https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls?hl=de)
- Robots (siehe https://developers.google.com/search/docs/advanced/robots/robots_meta_tag?hl=de)
- Hreflang-Informationen für internationale Websites (siehe https://developers.google.com/search/docs/advanced/crawling/localized-versions?hl=de)
Warum kann man diese Informationen über den HTTP-Header liefern?
Die Frage ist gerechtfertigt: Warum kann man derlei Daten in den HTTP-Header einbauen, wenn man sie auch im HTML-Code mitliefern kann? In welchen Fällen kann das sinnvoll sein?
Es gibt einen sehr guten Grund dafür: Wer z. B. eine PDF-Datei per „noindex“ sperren möchte, kann das über den Code nicht machen, weil Suchmaschinen nur HTML- und nicht PDF-Code auslesen. Außerdem gibt es im PDF-Code kein „noindex-Tag“. Die einzige Möglichkeit besteht dann eben darin, solche Informationen über den Header zu liefern.
Was passiert, wenn sich die Informationen widersprechen?
Es kann theoretisch passieren, dass im HTML-Code und im HTTP-Header widersprüchliche Informationen zu finden sind – also z. B. „index“ im HTML-Code und „noindex“ im Header. Das ist zwar sehr unwahrscheinlich, aber es könnte passieren. In solchen Fällen würde sich Google übrigens immer für die restriktivere Information entscheiden – also z. B. für „noindex“.
Theoretisch können im HTTP-Header aber auch Informationen zu finden sein, die im HTML-Code fehlen – z. B. weil sie unwissentlich dort eingebaut wurden. Dann kann das auch nachteilig sein. Das ist zwar nur eine theoretische Gefahr, aber gesehen habe ich solche Fälle in der Praxis leider schon.
Wie kann man die HTTP-Header einsehen?
Gängige SEO-Tools wie der Screaming Frog SEO Spider lesen die HTTP-Header aus und würden ein dort platziertes „noindex“ erkennen. Das Auslesen der Robots-Informationen aus dem Header kann man theoretisch über die Option „Configuration > Spider > Extraction > X-Robots-Tag“ ausschalten. Das sollte man natürlich niemals machen.
Wenn im HTTP-Header also SEO-relevante Informationen platziert sind, würde der Screaming Frog SEO Spider diese auch „sehen“. Wer zusätzlich aber auch einen eigenen Blick in den HTTP-Header werfen möchte, kann das über die Option „Configuration > Spider > Extraction > HTTP Headers“ machen:
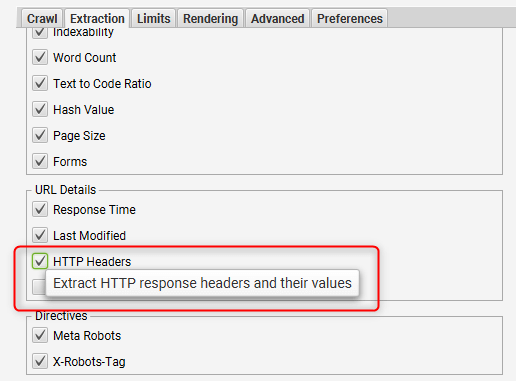
Wenn man diese Option gesetzt hat, kann man nach dem Crawlen über den Tab „HTTP Headers“ (untere Tab-Leiste) einen Blick auf Response (links) und Request (rechts) werfen:
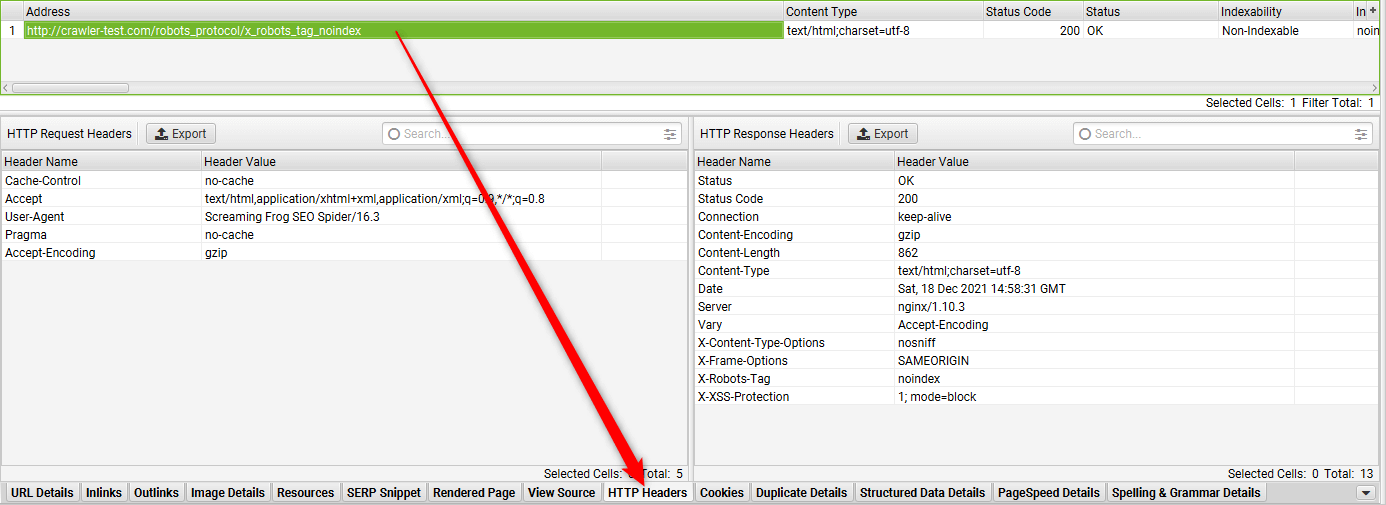
Was empfehle ich?
- SEO-Tools sollten immer so konfiguriert werden, dass sie die Daten aus den Headern auslesen. Ansonsten verhält sich das Tool anders als Google, was in der Regel nicht gewünscht ist.
- Bei einem SEO-Audit würde ich immer einen Blick in die HTTP-Header werfen – vorausgesetzt natürlich, dass man auch gut versteht, was die Informationen dort bedeuten. Wie gesagt: Die gängigen SEO-Tools extrahieren die Informationen in der Regel ohnehin, sodass man eigentlich keinen Blick in die Header werfen müsste. Aber für die Extraportion „peace of mind“ kann es sich durchaus lohnen.
- Falls möglich, würde ich auf die doppelte Auslieferung von Informationen in HTML-Code und HTTP-Header verzichten – und sei es nur, um ein paar Zeichen aus dem Übertragungsweg einzusparen.

Markus Hövener
Markus Hövener ist Gründer und SEO Advocate der auf SEO und SEA spezialisierten Online-Marketing-Agentur Bloofusion. Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Buchautor, Podcaster und Autor vieler Artikel und Studien rund um SEO.
Markus hat vier Kinder, spielt in seiner Freizeit gerne Klavier (vor allem Jazz) und genießt das Leben.
Neueste Artikel von Markus Hövener (alle ansehen)
- SEO-Trainee-Programme: Ganz einfach SEOs ausbilden? [Search Camp 316] - 16. April 2024
- SEO-Monatsrückblick März 2024: Google Updates, Search Console + mehr [Search Camp 315] - 2. April 2024
- Recap zur SMX München: Die wichtigsten Take-Aways [Search Camp 314] - 19. März 2024
- Sichtbarkeit und/oder Traffic gehen nach unten: Woran kann’s liegen? [Search Camp 313] - 12. März 2024
- Wie wichtig ist es, allen SEO-News zu folgen? [Search Camp 312] - 5. März 2024

März 8th, 2022 at 08:28
Sehr guter Artikel, leicht verständlich erklärt.
Den einen Fall hatte ich gestern sogar. Meta Index im html Beim robots Tag und noindex in der x-robots header Angabe. Wenn man da nicht gebaut hinschaut, übersieht man das leicht.
März 8th, 2022 at 08:35
Moin Alex,
passiert zum Glück selten – kann aber passieren!
Grüße, Markus