Teil 2 unserer Serie: www.bonprix.de unter der Lupe
Mann, seit ich weiß, dass Bonprix hier mitliest, bin ich ja schon etwas nervös. Aber wie gesagt: Es geht hier nicht um Meckern, sondern darum, typische Probleme/Überlegungen aufzuzeigen – und da haben wir hoffentlich einige gute Aspekte gefunden.
Der Einstieg
Bei www.bonprix.de fällt zunächst auf, dass der Browser beim Aufruf der Startseite umgeleitet wird. Da das mit verschiedenen Methoden geschehen kann (auch solchen, die Google nicht erkennen kann), prüfe ich zunächst die Weiterleitung: http://www.bonprix.de/ leitet per 301-Umleitung auf die Seite http://www.bonprix.de/bp/home.htm um:
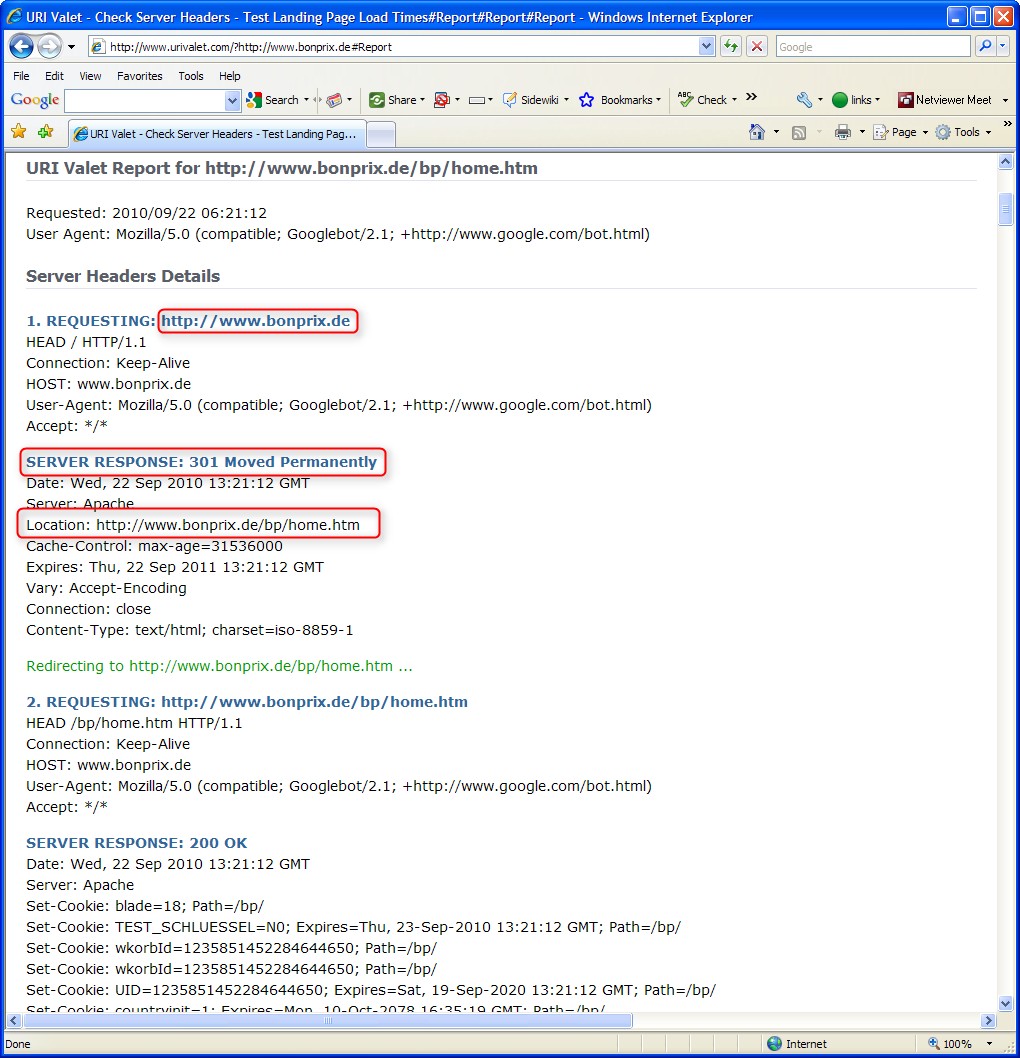
Google hat so kein Problem damit, also: alles bestens.
Fly-Out-Navigation
Dank des deaktivierten JavaScripts sieht man im Browser aber schnell etwas, was sonst nicht zu sehen wäre: Wie heutzutage üblich ist die so genannte Fly-Out-Navigation per CSS und JavaScript implementiert, was eben erst einmal nur dann zu sehen ist, wenn JavaScript deaktiviert ist. Alle Menüs sind ausgeklappt – und das ist auch genau das, was Google sieht:
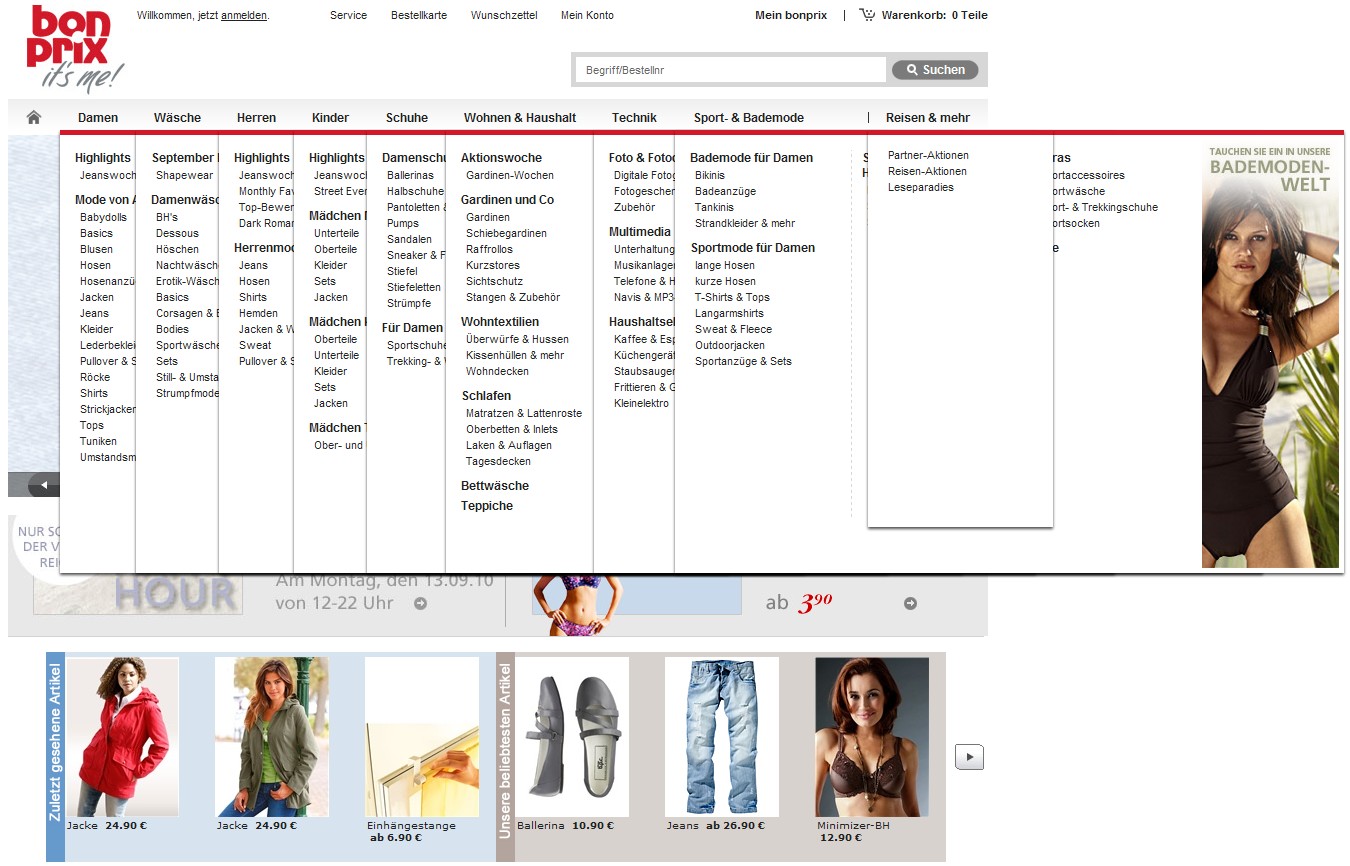
Jede Seite der Website, die die Fly-Out-Navigation beinhaltet, verlinkt damit auf ca. 100 Unterseiten. Das kann problematisch sein, weil dann allen verlinkten Unterseiten dasselbe Linkgewicht zukommen würde. Eine Oberrubrik wie “Damen” (sehr wichtig) und eine Unterrubrik wie “Leseparadies” hätten also dasselbe Linkgewicht.
Ob und in welcher Form das schädlich ist, ist umstritten. Da Google per Page Segmentation Seitenbestandteile in konstant (Footer, Top-Navigation, …) und variabel (Content-Bereich, Breadcrumbs, …) unterscheiden kann, ist es wahrscheinlich, dass konstante Elemente weniger Linkgewicht weitergeben können als Links im variablen Bereich. Ob Google allerdings auf diesem Wege eine solche Fly-Out-Navigation erkennen kann und dann die Links entsprechend gewichtet, ist wie gesagt umstritten und auch nur mit hohem Aufwand zu überprüfen.
Wer sich hier auf keine Experimente einlassen möchte, sollte also auf eine derart implementierte Navigation verzichten und die Funktionalität eher auf anderem Wege (z.B. per JavaScript) erzeugen.
Parameter, Session-IDs
Wer sich die URLs der Oberrubriken anschaut, entdeckt hier schon schnell ein potenzielles Problem:
- http://www.bonprix.de/bp/Damen-1-shop.htm?sourcePageClick=tab1
- http://www.bonprix.de/bp/Waesche-2-shop.htm?sourcePageClick=tab2
- http://www.bonprix.de/bp/Herren-3-shop.htm?sourcePageClick=tab3
- …
Über den Parameter “sourcePageClick” will Bonprix offensichtlich tracken, wie jemand auf eine bestimmte Seite kommt. Da aber dieser Parameter verschiedene Werte annehmen kann, ist das natürlich eine Quelle für doppelten Content. Es empfiehlt sich dann, diesen Parameter über die Google Webmaster Tools als zu ignorierenden Parameter zu setzen (“Parameterbehandlung”) und parallel auf jeden Fall ein Canonical-Tag zu nutzen, um einer Seite wie http://www.bonprix.de/bp/Damen-1-shop.htm?sourcePageClick=tab1 die “richtige” URL (http://www.bonprix.de/bp/Damen-1-shop.htm) mitzugeben. Ein Canonical-Tag ist aber nicht zu finden, was in diesem Fall ein schlechtes Zeichen ist.
Wer jetzt also die URL http://www.bonprix.de/bp/Damen-1-shop.htm?sourcePageClick=tab1 daraufhin überprüft, ob Google diese indexiert hat, kann dies über die Suchanfragen “info:URL” bei Google machen. In der Regel sollte man dann direkt ein Suchergebnis mit der angefragten URL bekommen – nicht so bei bonprix.de. Google kennt offensichtlich eine Menge an Seiten, die zu der angefragten URL passen, z. B.
http://www.bonprix.de/bp/Schuhe-5-shop.htm?sourcePageClick=tab5&id=1687817532747634965-0-4c7a4529
http://www.bonprix.de/bp/Schuhe-5-shop.htm?sourcePageClick=tab5&id=1101501380635024948-0-4c59fe6c
…
Dabei sieht man, dass Google diese Ergebnisse ohne Snippet anzeigt:
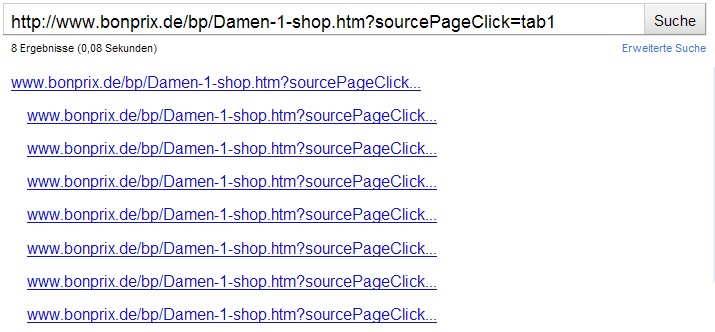
Das ist ein klares Indiz dafür, dass diese Seiten für Suchmaschinen gesperrt sind – was auch stimmt: In der robots.txt findet sich der Eintrag “Disallow: *id=*”, der dafür sorgt, dass URLs mit dem Parameter “id” nicht gecrawlt werden dürfen. Aber warum sind diese dann trotzdem im Google-Index?
Das liegt daran, dass Google zwischen Crawling und Indexing unterscheidet. Die robots.txt verhindert zunächst nur das Crawling, also dass Google bzw. der Googlebot die entsprechenden Seiten vom Server herunterladen. Nicht verhindert wird jedoch, dass Google dafür trotzdem Index-Einträge anlegt.
Also: Man hat hier die für Online-Shops typische Probleme mit Session-IDs (zumindest darf vermutet werden, dass sich hinter dem Parameter “id” eine solche verbirgt). Das Problem sollte aber nicht unbedingt dadurch gelöst werden, dass Seiten mit dem Parameter “id” für Suchmaschinen gesperrt werden.
Viele Shops lösen das Problem z. B. dadurch, dass einem Besucher, der sich über den User-Agent als Googlebot erkenntlich gibt, eine fixe Session-ID (etwa “id=bot” mitgegeben wird). Alternativlösungen können aber auch einfach darin bestehen, dass der Parameter “id” als zu ignorierender Parameter definiert wird. Auch ein Canonical-Tag kann hier helfen.
Trotzdem: Die optimale Lösung besteht natürlich nach wie vor darin, überhaupt keine Session-IDs in URLs zu führen. Das aber erlauben nicht alle Shop-Systeme.
Varianten
Bei Bonprix besteht auch noch ein weiteres Problem, das primär Shops und da vor allem solche aus dem Modebereich haben: So gibt es ein Produkt oft in mehreren Varianten (Farbe, Größe, …). Bei Bonprix gibt es z. B. eine Jacke in unterschiedlichen Farben:
- http://www.bonprix.de/bp/Jacke-2507497-bundle.htm?&oItem=94752595&bu=2507497
- http://www.bonprix.de/bp/Jacke-2507497-bundle.htm?&oItem=94783395&bu=2507497
- http://www.bonprix.de/bp/Jacke-2507497-bundle.htm?&oItem=94458195&bu=2507497
Der Parameter “bu” ist fix und enthält wohl eine Datenbank-ID des Produkts, während “oItem” die Variante identifiziert. Problematisch kann das werden, weil hier eben wieder Duplicate Content erzeugt wird. Die Seiten sind bis auf die Farbe identisch – und diese findet sich manchmal nur im veränderten Bild wieder.
Da das Produkt auch unter der URL http://www.bonprix.de/bp/Jacke-2507497-bundle.htm?bu=2507497 erreicht werden kann, könnte Bonprix hier zwei Lösungswege wählen:
- Alle Seiten erhalten dasselbe Canonical Tag (und zwar http://www.bonprix.de/bp/Jacke-2507497-bundle.htm?bu=2507497)
- Der Parameter “oItem” wird als zu ignorierender Parameter in den Google Webmaster Tools definiert
Soft-404s
Wer sich die Mühe macht und einmal nach einer Produktbeschreibung bei Google sucht, findet leider die dazugehörigen Produktseiten manchmal nicht im Index. Die Suchanfrage
“Tunnelzug in der Kapuze und Taille zur individuellen Weitenregulierung” site:bonprix.de
zeigt sehr viele Seiten auf – nur eben manchmal nicht die gesuchte Produktseite.
Dafür findet man ein neues Problem: Es gibt im Google-Index URLs wie www.bonprix.de/bp/Jacke-4691932-style.htm, die auf eine Fehlerseite verweisen (“Die Seite konnte leider nicht gefunden werden.”). Diese Fehlerseite liefert aber leider keinen 404-Code, sondern einen 200-Code, so dass Google annimmt, dass diese URLs richtig sind. So wird es leider niemals dazu kommen, dass Google nicht mehr gültige URLs aus dem Index entfernt.

Fazit
Es scheint hier sehr viele – für Online-Shops nicht untypische – Probleme zu geben. Die meisten davon dürften auf das Shop-System zurückzuführen sein. Die genannten Probleme (Session-IDs, Varianten, …) sind allerdings allesamt bekannt und werden von vielen Shop-Systemen auch mittlerweile recht gut gelöst.

Markus Hövener
Markus Hövener ist Gründer und SEO Advocate der auf SEO und SEA spezialisierten Online-Marketing-Agentur Bloofusion. Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Buchautor, Podcaster und Autor vieler Artikel und Studien rund um SEO.
Markus hat vier Kinder, spielt in seiner Freizeit gerne Klavier (vor allem Jazz) und genießt das Leben.
Neueste Artikel von Markus Hövener (alle ansehen)
- SEO-Trainee-Programme: Ganz einfach SEOs ausbilden? [Search Camp 316] - 16. April 2024
- SEO-Monatsrückblick März 2024: Google Updates, Search Console + mehr [Search Camp 315] - 2. April 2024
- Recap zur SMX München: Die wichtigsten Take-Aways [Search Camp 314] - 19. März 2024
- Sichtbarkeit und/oder Traffic gehen nach unten: Woran kann’s liegen? [Search Camp 313] - 12. März 2024
- Wie wichtig ist es, allen SEO-News zu folgen? [Search Camp 312] - 5. März 2024

September 22nd, 2010 at 16:08
Zum Punkt Parameter, Session-IDs
Klar sind wir uns alle einig das Session-IDs nur bedingt auf eine Website gehören. In diesem Fall kann aber, sofern man diese behalten will, die Lösung in der Kombination liegen:
– robots Auscchluss
– Webmastertools Ausschluss
– Canonial
– Meta-Tag Noindex (diesen hattest du nicht mit aufgezählt)
Ich pers. würde immer alle 4 Möglichkeiten nutzen sofern man nicht auf diese IDs verzichten kann, da einzelne Lösungen ja nicht immer funktionieren.
Hatte grade bei einem Kunden das Problem das ein noindex und canonical nichts bewirkt.. die Seite rankt seit Wochen noch immer in den Top10.
September 22nd, 2010 at 16:43
hallo herr hövener,
vielen dank für ihre analyse. 🙂 die von ihnen aufgeführten probleme sind uns natürlich zum grössten teil bekannt, das thema session id wird bei uns mithilfe einer bot erkennung behandelt.
man findet im index leider noch immer seiten mit einer session id, dieses ist das ergebnis unseres relaunchs. in dieser zeit haben einige SEO programme innerhalb unseres shops ihren dienst verweigert. 🙂 …ärgerlich.
das thema canonical tag hatten wir bis zum besagten relaunch auch implementiert, doch leider kam es zu “unstimmigkeiten” in unserer navigation und der internen weiterleitung, so daß wir beschlossen hatten den canonical tag bis zur bereinigung raus zu nehmen.
ihre anderen punkte haben wir als denkanstoß aufgenommen und werden sicherlich in der zukunft noch die eine oder andere änderung vornehmen.
danke auch für ihre sachliche darstellung!
viele grüße
matthias hartz
September 22nd, 2010 at 16:49
@Matthias: Gern geschehen.
@fiacyberz: Noindex habe ich nicht aufgeführt, weil ich’s nicht noch komplexer machen wollte. Wenn man verhindern will, dass die Seiten in den Index kommen, müsste man ja ein Noindex setzen. Das geht aber nicht parallel zur robots.txt, weil Google ja sonst die Seite nicht abholen kann, um zu sehen, dass dort ein Noindex drin ist.
September 22nd, 2010 at 18:22
Stimmt wenn sich der Bot wirklich so verhält wie sie es immer sagen bei Google. Halte ich hier jedoch für ein Gerücht, daher würde ich beides gleichzeitig einsetzen.
Wäre mal ein größerer Test interessant.
September 23rd, 2010 at 07:03
Hallo Markus,
schöner Analyse-Artikel, der auch mal auf den Punkt kommt. Beispiele aus der Praxis sind immer noch am besten. Shop-Software “out of the box” kann doch wirklich häufig Probleme bereiten, zumindest hinsichtlich SEO.
Grüße aus Düsseldorf,
Roland Schupp
September 23rd, 2010 at 12:50
Moin Markus,
vielen Dank für den konkreten und gut recherchierten Case. Man könnte sagen, dass diese Ausführungen für die Betreiber der Site fast schon bares Geld wert sind 🙂
Grüßle aus dem Süden,
SouthSEO
September 23rd, 2010 at 15:56
Naja, wir machen solche Analysen ja auch gerne für Geld *HINT* *HINT* *HINT* …
September 27th, 2010 at 19:20
Nein, Markus nein. Wie kannst du nur 🙂
September 27th, 2010 at 19:22
Sorry, aber das Haus & die Kinder & die Frau… kostet alles…
Oktober 17th, 2010 at 01:42
Hi,
weiß jemand von euch ob Google den vollen Startseitentrust weitergibt, wenn von der Startseite per 301 auf eine Unterseite geleitet wird? Ich hab wohl mal einen Versuch gemacht und dann festgestellt, dass Google die Unterseite auch in den Serps weiterhin mit der normalen TLD verlinkt, aber was den Trustfaktor angeht kam ich zu keinem klaren Ergebnis.
Vielen Dank!
Oktober 18th, 2010 at 06:05
Ich glaube, dass Google die Umleitung einer Startseite separat handelt, weil hier z.B. auch 301 und 302 gleichermaßen funktionieren. Ich glaube daher auch, dass – weil eben so viele die Startseite umleiten – Google hier auch Trust, etc. 1:1 weiterreicht, ohne dass unterwegs etwas verlorengeht.